Hugging Face ha aggiunto un tassello che mancava da tempo al proprio ecosistema: uno strato di storage pensato non per i modelli finali, ma per tutto quello che succede prima. Con Storage Buckets, la piattaforma introduce contenitori non versionati e mutabili, accessibili via interfaccia web, CLI e API, destinati a checkpoint, shard di dataset, log, trace degli agenti e artefatti intermedi di pipeline ML. È una novità meno appariscente di un nuovo modello di frontiera, ma molto più rivelatrice del punto in cui sta andando il mercato.
Il problema che Hugging Face prova a risolvere è semplice: Git funziona bene quando bisogna pubblicare un artefatto stabile, molto meno quando un training job scrive continuamente file pesanti, li sovrascrive, li sincronizza tra job diversi e poi li scarta. In quella zona operativa, che oggi vale una quota crescente dei costi e della complessità dei team AI, serve altro. Storage Buckets entra precisamente lì.
Indice
- Cosa cambia rispetto ai repository tradizionali
- Perché conta per chi costruisce prodotti AI
- Il vero segnale: Hugging Face si allarga verso l’infrastruttura
Cosa cambia rispetto ai repository tradizionali
La distinzione fatta da Hugging Face è netta. I repository classici restano il luogo della pubblicazione: modelli, dataset, Spaces, versioning, collaborazione, card, pull request. I Buckets invece sono l’area di lavoro ad alta frequenza: niente cronologia Git, niente commit come unità centrale, niente overhead pensato per artefatti che cambiano di continuo.
Nel post di annuncio e nella documentazione ufficiale, Hugging Face insiste su tre elementi. Il primo è la mutabilità: i file possono essere aggiornati o rimossi in-place, come in uno storage object classico. Il secondo è l’integrazione con strumenti che i team già usano davvero, come hf buckets sync, Python e filesystem compatibili con fsspec. Il terzo è Xet, il backend chunk-based che deduplica a livello di contenuto e rende meno costosa la gestione di famiglie di file molto simili tra loro, per esempio checkpoint successivi o dataset raw e processed con ampia sovrapposizione.
Non è un dettaglio tecnico per addetti ai lavori. Significa ridurre traffico inutile, tempi di trasferimento e, almeno sui piani enterprise, anche il footprint fatturato quando gli artefatti condividono buona parte dei chunk. Hugging Face lo presenta come un vantaggio strutturale per carichi ML reali, non come una finezza da benchmark.
Perché conta per chi costruisce prodotti AI
Negli ultimi dodici mesi il lavoro sui modelli si è spostato sempre di più dalla fase di rilascio alla fase di orchestrazione. Non basta avere un modello valido: bisogna gestire pipeline dati, versioni parziali, cache, evaluation set, rollout graduali, ambienti multi-cloud e ora anche agenti che producono memoria, trace e output intermedi. In questo contesto, l’infrastruttura di appoggio diventa parte del prodotto.
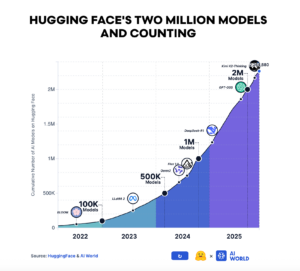
Hugging Face lo sa bene. Nel suo recente report sullo stato dell’open source sulla piattaforma, la società scrive che l’ecosistema è cresciuto fino a 13 milioni di utenti, oltre 2 milioni di modelli pubblici e più di 500 mila dataset pubblici, con un aumento forte degli artefatti derivati e delle specializzazioni. Tradotto: non cresce solo il catalogo, cresce il lavoro operativo che ruota attorno a quel catalogo. Storage Buckets è la risposta a questa pressione.
C’è poi il tema economico. La pagina pricing dedicata allo storage parla di una base da 12 dollari per TB al mese per i bucket pubblici e 18 dollari per quelli privati, con sconti progressivi a volume e CDN inclusa. La comparazione implicita è con l’idea di tenere tutto in repository versionati o in stack esterni frammentati. Per un team che già vive nel mondo Hugging Face, la promessa è chiara: meno attrito tra fase di lavoro e fase di pubblicazione, senza uscire dall’ecosistema.
Questo interessa soprattutto chi sviluppa prodotti AI in produzione, ma anche chi lavora su coding agents, sistemi documentali, pipeline di eval e dataset engineering. Se un’infrastruttura nasce per conservare non solo i pesi finali ma il materiale vivo che li circonda, allora non sta più servendo la community soltanto come vetrina di modelli: sta provando a diventare il layer operativo su cui scorrono gli esperimenti.
Il vero segnale: Hugging Face si allarga verso l’infrastruttura
Qui sta il punto editoriale più interessante. Per anni Hugging Face è stata raccontata soprattutto come il “GitHub dei modelli”. Definizione utile, ma ormai stretta. Con Buckets la piattaforma si sposta un passo più vicino al cuore infrastrutturale del ciclo AI: non soltanto hosting, discovery e distribuzione, ma gestione del lavoro sporco che precede un rilascio stabile.
Anche il lessico usato nell’annuncio è indicativo. Si parla esplicitamente di training clusters, processed shards, agent traces, pre-warming vicino al compute su AWS e GCP, e di un futuro collegamento diretto tra bucket e repository versionati. È la grammatica di un’infrastruttura che vuole stare accanto ai workload enterprise, non solo alla community open.
Le fonti seed di scouting raccontano bene il contesto. Hugging Face Community Blog offre il dato più sostanziale. Aibase segnala la notizia dentro il flusso quotidiano del mercato AI, confermando che il lancio è percepito come una release di prodotto rilevante. TechCrunch, pur senza un pezzo verticale utile su questo tema nel feed AI consultato, resta utile come cartina di tornasole: oggi le novità che contano non sono solo i modelli migliori, ma gli strumenti che rendono sostenibile usarli davvero.
Per questo Storage Buckets merita attenzione. Non perché cambi da solo la gerarchia dell’AI, ma perché mostra dove si sta spostando il valore: verso servizi che riducono attrito operativo, consolidano workflow e tengono insieme dati, training, agenti e pubblicazione finale. In altre parole, la competizione non passa più soltanto dai modelli. Passa sempre di più dalla qualità dell’infrastruttura che li rende utilizzabili.